1. Introduction
Wildlife monitoring plays a pivotal role in conservation efforts, helping researchers gather critical data on animal populations, behaviors, and habitats. Traditional object detection methods, while useful, often struggle with the complexity of natural environments, leading to less accurate results. To address this, a groundbreaking approach called SW-YOLO has been developed, combining the strengths of two powerful AI models: SAM (Segment Anything Model) for image segmentation and YOLO (You Only Look Once) for object detection. This integration promises to significantly improve the accuracy of wildlife detection by reducing the interference of environmental elements.
2. The Challenge of Environmental Complexity
Monitoring wildlife in their natural habitats presents unique challenges. Animals often blend into their surroundings, making it difficult for detection algorithms to distinguish them from the background. This results in higher rates of false positives and negatives, which can skew monitoring data and conservation efforts. The YOLO algorithm, despite its speed and accuracy, is not immune to these issues, particularly when dealing with complex environmental information.
3. The SW-YOLO Solution
SW-YOLO offers an innovative solution to these challenges by first employing SAM to segment animal images from their backgrounds, thus creating high-quality animal masks. These masks are then used to focus the YOLO algorithm on the animals themselves, significantly reducing the distractions of the surrounding environment.
4. Dataset Diversity
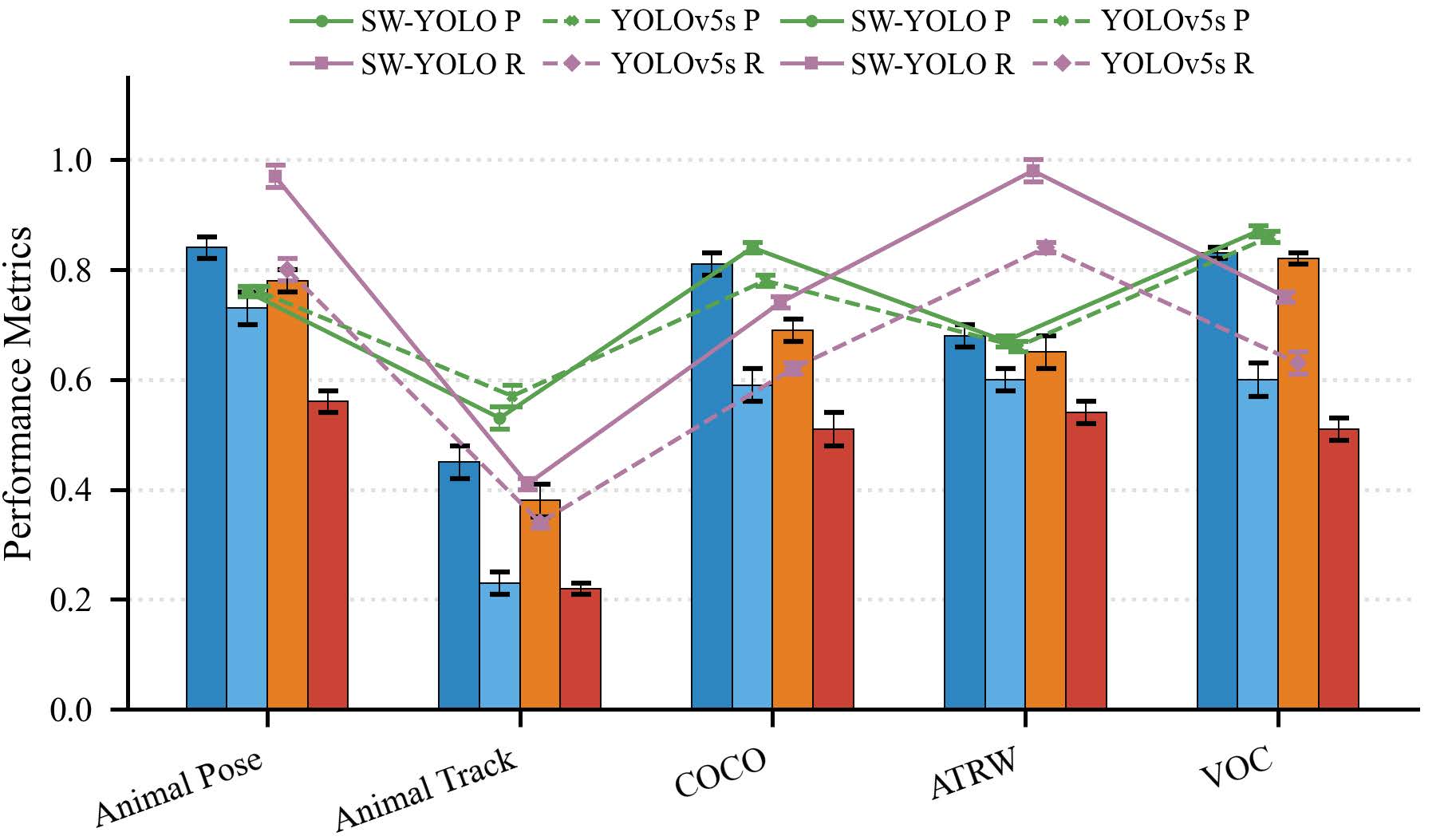
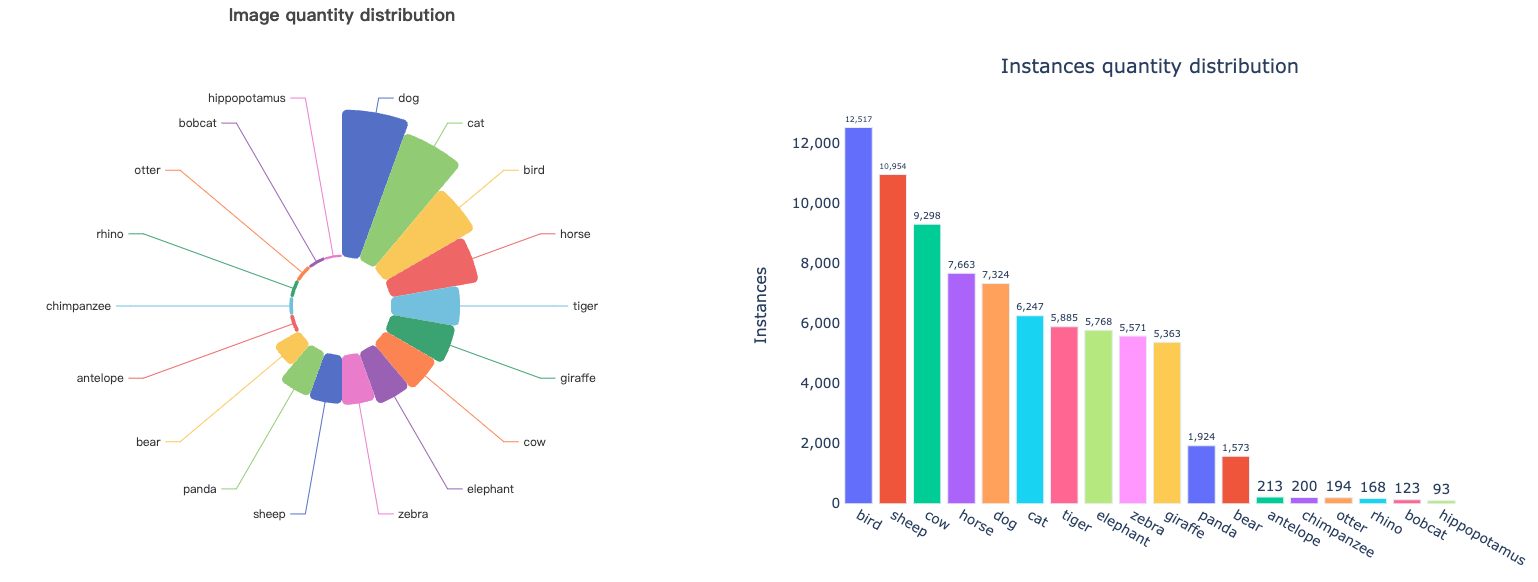
To ensure the robustness of SW-YOLO, extensive testing was conducted across four diverse datasets, including general data and specific animal data. These datasets encompass a range of species and environments, from the expansive ATRW dataset featuring Amur tigers to the Animal Pose datasets, which cover various wildlife species with accurately annotated bounding boxes. This comprehensive testing confirms SW-YOLO’s effectiveness across different scenarios.
| Name | #Categories | Data size | #BBoxes |
|---|---|---|---|
| Animal Pose | 7 | 366MB | 970 |
| ATRW | 1 | 2.5GB | 10,009 |
| MS COCO 2017 | 10 | 4.3GB | 65,266 |
| Pascal VOC 2012 | 6 | 507MB | 6,804 |


5. The SW-YOLO Architecture
5.1. Input Processing
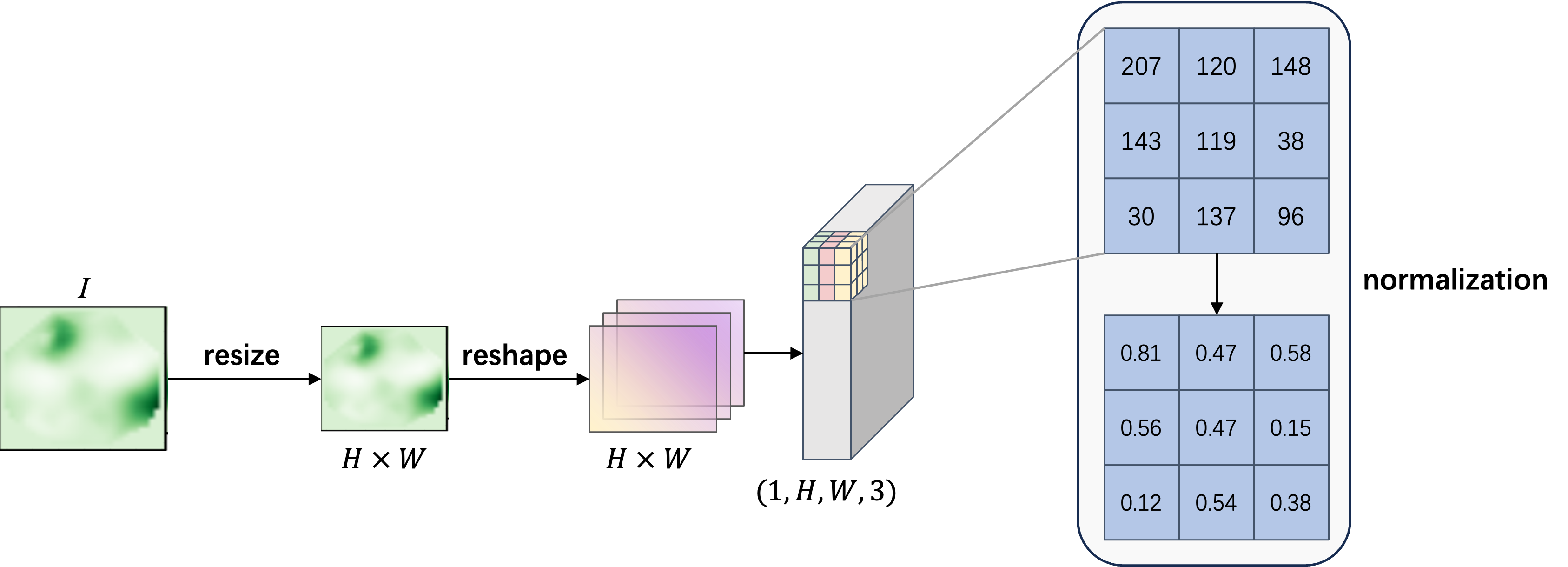
In order to ensure that input images are properly processed, a preprocessing routine is implemented. The preprocessing steps begin with resizing the input image, denoted as $I$, to a predetermined height and width $H\times W$ using bilinear interpolation. This interpolation method is mathematically represented by the equation below,
where $Q(x,y)$ is the value of the target pixel, $P(x,y)$ is the value of the original image pixel, and $\alpha$ and $\beta$ are the horizontal and vertical offsets of the target pixel position from its nearest neighbors. The coordinates $(x_1,y_1,x_2,y_2)$ correspond to the positions of the four closest neighboring pixels around the target pixel.
Following the resizing, the image is reshaped into a 4-dimensional array with the dimensions $(1,H,W,3)$, where $1$ indicates that there is only one image in the batch, and $3$ denotes the three channels of an RGB image. This array is then converted into a tensor to facilitate subsequent calculations and processing steps. Finally, pixel values are normalized by dividing by 255, scaling them to a range between 0 and 1. This normalization is beneficial for neural network computations, as it ensures that the input values are within a range that is typically expected by the network’s architecture.
5.2. Overview of SW-YOLO
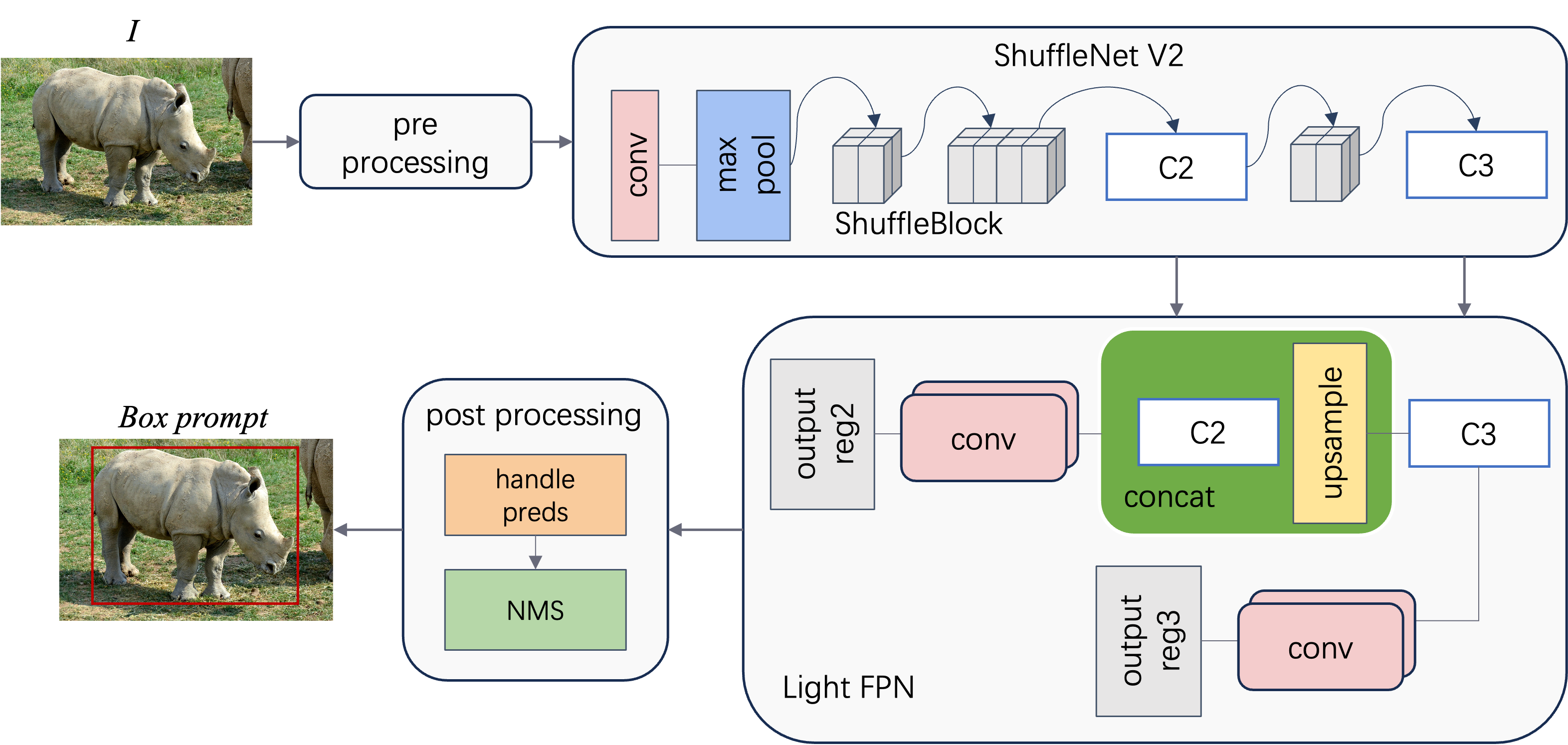
The SW-YOLO system is composed of three main components: the SW-Prompter, SAM, and YOLO. The SW-Prompter automatically generates bounding box prompts for SAM, which then segments the animals in the images. These segmented images are weight-adjusted and fed into the YOLO model for final object detection. This streamlined process ensures that the focus remains on the wildlife, leading to more accurate detection outcomes.
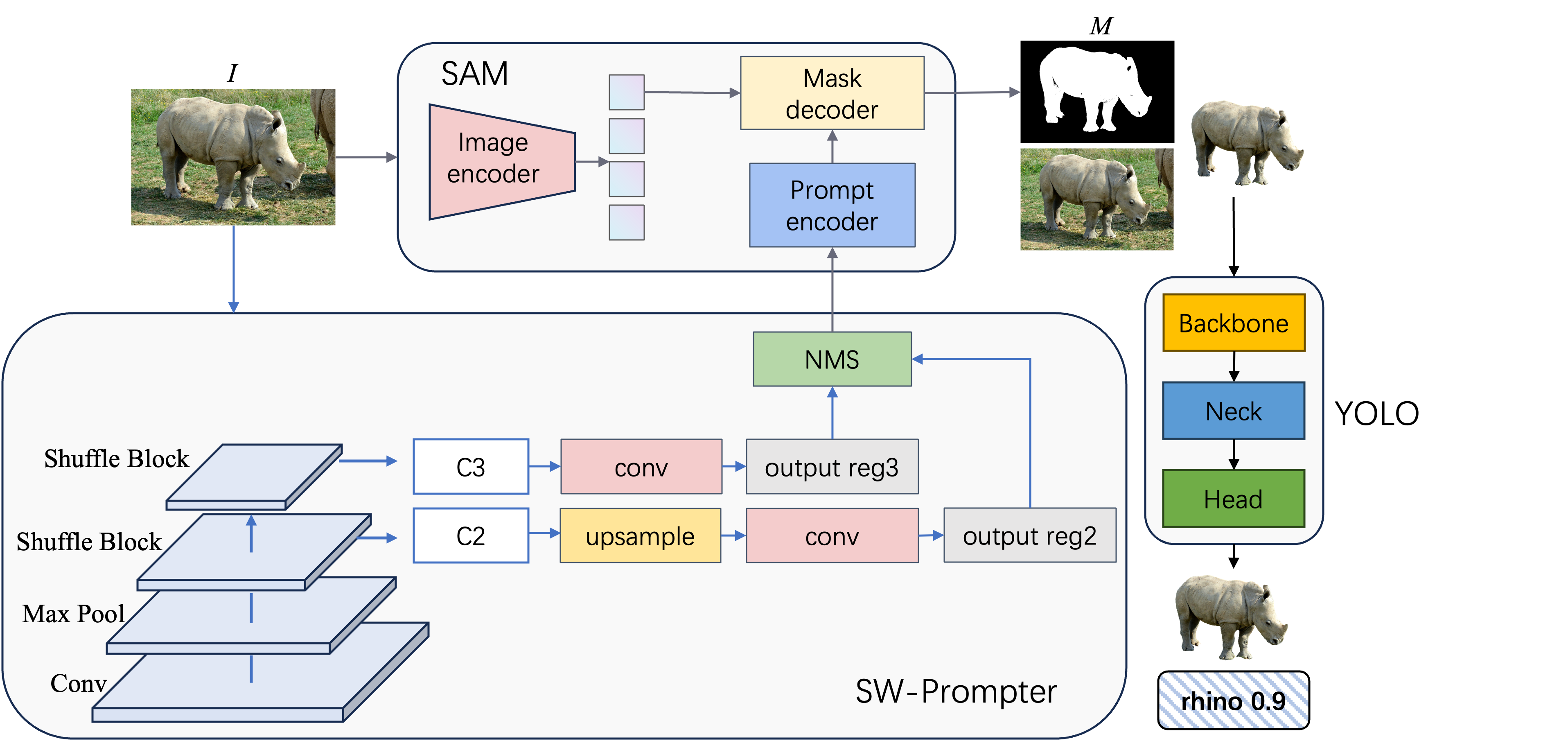
5.3. SW-Prompter
The SW-Prompter utilizes a lightweight yet powerful neural network, ShuffleNetV2, as its backbone. This network is chosen for its balance between computational efficiency and the ability to extract rich features from images, which is essential for generating accurate prompts in the form of bounding boxes. The process begins with the ShuffleNetV2 backbone extracting high-level features from the input image. These features are then passed through a series of ShuffleBlocks, which are the core building blocks of ShuffleNetV2. ShuffleBlocks utilize a novel channel shuffle operation that allows for the efficient recombination of features across channel groups, enhancing the flow of information and improving the network’s representational capabilities. Once the features are extracted and processed, they are fed into a lightweight feature pyramid network (LightFPN). The LightFPN is responsible for integrating multi-scale features and producing a more comprehensive representation that is crucial for accurate bounding box prediction. The network employs a top-down architecture with lateral connections, enabling the precise localization of objects at various scales.
6. Multimodal Exploration
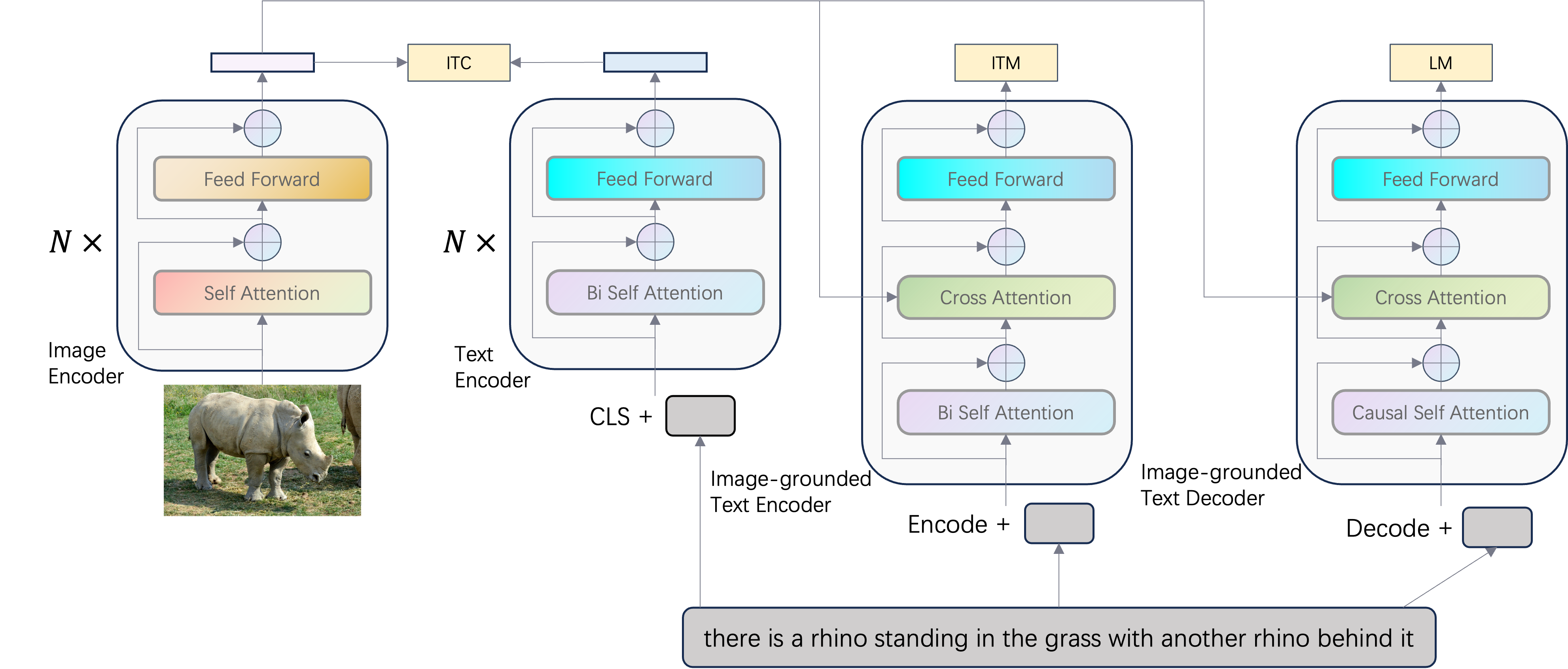
In our research, we harness the power of BLIP (Bootstrapping Language-Image Pre-training) to delve into the multimodal dimensions of image analysis. BLIP’s advanced pre-training on text-image pairs empowers it to articulate detailed and contextually relevant descriptions of visual content, effectively bridging the gap between visual data and linguistic interpretation. By fine-tuning BLIP on specialized datasets, we tailor its descriptive prowess to our specific research needs, enabling nuanced image understanding and subsequent mining of textual annotations for deeper insights. This multimodal approach not only enriches our data analysis but also unveils latent semantic layers, offering a comprehensive perspective on the visual information at hand.
7. Summary
SW-YOLO marks a significant step forward in intelligent wildlife monitoring. By leveraging the segmentation power of SAM and the detection capabilities of YOLO, this method reduces the impact of environmental noise and focuses on the animals themselves. The substantial improvements in accuracy, as demonstrated by the experimental results, highlight the potential of SW-YOLO to revolutionize wildlife monitoring and contribute to the preservation of biodiversity. As we continue to refine AI and computer vision technologies, methods like SW-YOLO pave the way for more effective conservation strategies, allowing us to protect and understand our planet’s wildlife better than ever before.